【机器学习从入门到入土】
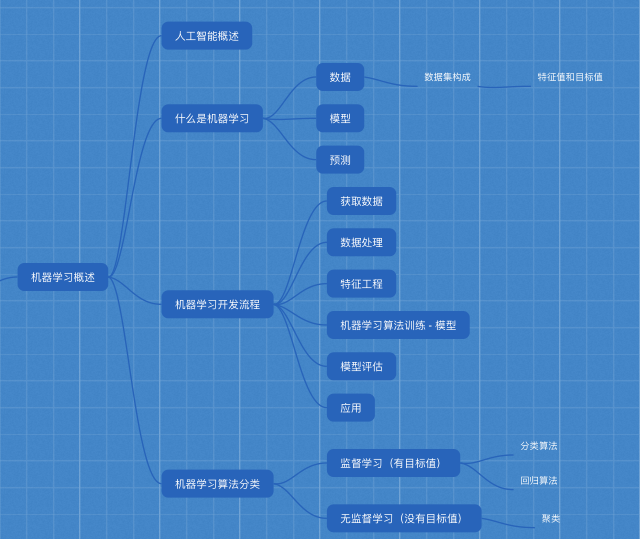
一、机器学习概述
1.什么是机器学习?
机器学习是从大量的数据中自动分析获得规律(模型),并利用规律对未知数据进行预测。
2.机器学习应用场景?
机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人等领域.
3.机器学习算法分类
监督学习(Supervised learning),可以由输入数据中学
到或建立一个模型,并依此模式推测新的结果。输入数据是由
输入特征值和目标值所组成。函数的输出可以是一个连续的值
(称为回归),或是输出是有限个离散值(称作分类)。
分类算法: k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
回归算法: 线性回归、岭回归无监督学习:可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。
聚类算法 K-means
4.开发机器学习应用程序的步骤
(1)收集数据
我们可以使用很多方法收集样本护具,如:制作网络爬虫从网站上抽取数据、从RSS反馈或者API中得到信息、设备发送过来的实测数据。
(2)准备输入数据
得到数据之后,还必须确保数据格式符合要求。
(3)分析输入数据
这一步的主要作用是确保数据集中没有垃圾数据。如果是使用信任的数据来源,那么可以直接跳过这个步骤
(4)训练算法
机器学习算法从这一步才真正开始学习。如果使用无监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容在第(5)步
(5)测试算法
这一步将实际使用第(4)步机器学习得到的知识信息。当然在这也需要评估结果的准确率,然后根据需要重新训练你的算法
(6)使用算法
转化为应用程序,执行实际任务。以检验上述步骤是否可以在实际环境中正常工作。如果碰到新的数据问题,同样需要重复执行上述的步骤
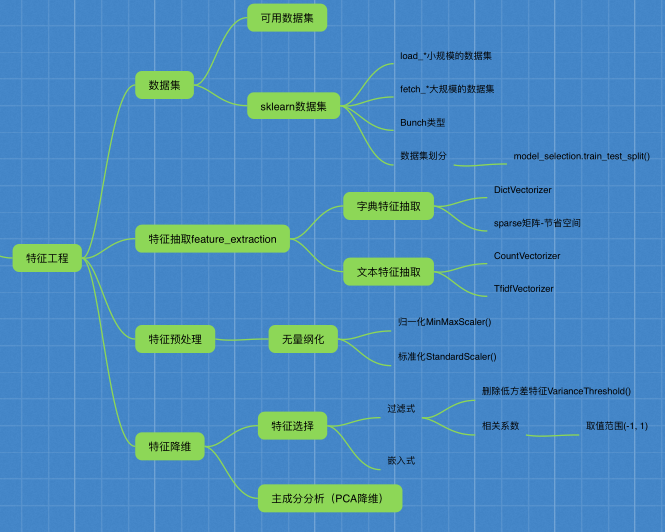
二、特征工程
2.1 数据集
1.Scikit_learn工具
python语言的机器学习工具
2.sklearn数据集的使用
sklearn数据集使用举例(以鸢尾花数据集举例)
1 | |
3.数据集的划分
机器学习一般的数据集会划分为两部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
sklearn.model_selection.train_test_split(arrays,*option)
·test_size 测试集的大小
·random_state 随机数种子,不同的种子会造成不同的随机采样结果,相同的种子采样结果相同。
·return 训练集特征值,测试集特征值,训练集目标值,测试集目标值
1 | |
2.2 特征工程介绍
1.为什么要有特征工程
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限
2.什么是特征工程
从数据中抽取出来对预测结果有用的信息,通过专业的技巧进行数据处理,使得特征能在机器学习算法中发挥更好的作用的过程。
3.特征工程的意义
更好的特征意味着更强的鲁棒性
更好的特征意味着只需用简单模型
更好的特征意味着更好的结果
4.特征抽取
(1)什么是特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取.
(2)特征提取API
sklearn.feature_extraction
字典特征提取
作用:对字典数据进行特征提取
sklearn.feature_extraction.DicVectorizer() 转换器类
操作流程:1
2
3
4
5
6
7
8data = [{'city': '北京','temperature':100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=True)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray(), type(data_new))
#需要toarray()方法转变为numpy的数组形式
print("特征名字:\n", transfer.get_feature_names())应用场景:
1.数据集当中类别特征比较多
将数据集的特征转换为字典类型
字典特征提取
2.本身拿到的数据就是字典类型文本特征提取
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
作用:对文本数据进行特征化,对中文特征化要事先分词用jiebasklearn.feature_extraction.text.CountVectorizer()

1
2
3
4
5
6
7data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["is", "too"])
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())中文特征处理
中文进行特征化之前要先用Jieba进行分词处理
jieba的使用:1
2
3
4
5
6"""
进行中文分词:"我爱北京天安门" --> "我 爱 北京 天安门"
:param text:
:return:
"""
return " ".join(list(jieba.cut(text)))1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20"""
中文文本特征抽取,自动分词
:return:
"""
# 将中文文本进行分词
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 1、实例化一个转换器类
transfer = CountVectorizer(stop_words=["一种", "所以"])
# 2、调用fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())上述运行结果:

Tf-idf文本特征提取
思想:如果某一词在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为该词有很好的类别区分能力,适合用来分类。
作用:用以评估一字词对于一个文件集或与个语料库中的其中一份文件的重要程度。
如果想找到文章中的关键词可以使用TfidfVectorizer
TfidfVectorizer会根据指定的公式将文档中的词转换为概率表示。
class sklearn.feature_extraction.text.TfidfVectorizer()
1 | |
5.特征预处理
当特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级时,容易影响目标结果,使得算法无法学习到其他特征,这时就要通过一些转换函数将特征数据转换称更加适合算法模型的特征数据。
归一化
通过对原始数据进行变换把数据映射到(默认[0,1])之间。
常用的方法是通过min-max方法对原始数据进行线性变换把数据映射到[0,1]之间,变换的函数为:
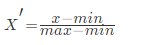
缺点:最大值与最小值会受到异常点的影响,这种方法的鲁棒性较差,知识和传统精确小数据场景
API:
scikit-learn.preprocessing中的类MinMaxScaler,将数据矩阵缩放到[0,1]之间
sklearn.preprocessing,MinMaxScaler(feature_range=(0,1)..)1
2
3
4
5
6
7
8
9
10# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = MinMaxScaler(feature_range=[2, 3])
feature_range定义了期望的结果范围
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1
处理方法:
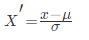
其中μ是样本的均值,σ是样本的标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景.
API:
sklearn中提供了StandardScalar类实现列标准化:
sklearn.preprocessing.StandardScaler()

1
2
3
4
5
6
7
8
9
10
11# 1、获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2、实例化一个转换器类
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)降维
在某些限定条件下,降低随机变量(特征)个数,得到一组不相关主变量的过程。
我们在进行训练的时候,我们都是使用特征进行学习,如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
降维两种方式:
特征选择
主成分分析
6.特征选择
sklearn.feature_selection
数据中包含冗余或相关变量,特征选择旨在从原有特征中找出主要特征。
特征选择主要有两个功能:
(1)减少特征数量,降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解
降维本质上是从一个维度空间映射到另一个维度空间,特征的多少并没有减少,当然在映射的过程中特征值也会相应的变化。
对于通过特征选择来降维,有很多方法:
(1) Filter(过滤式):
主要探究特征本身特点、特征与特征和目标值之间关联
·方差选择法:低方差特征过滤
·相关系数
低方差特征过滤
删除低方差的一些特征,VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。
sklearn.feature_selection.VarianceThreshold(threshold=0.0)

相关系数
皮尔逊相关系数:反映变量之间相关关系密切程度的统计指标
特点:
API:
from scipy.stats import pearsonr
1 | |
(2) Embedded(嵌入式):
VarianceThreshold
·算法自动选择特征(特征与目标是之间的关联)
·正则化、决策树
·深度学习:卷积
(3) Wrapper(包裹式)
7.主成分分析PCA
高维数据转换为低维数据的过程可能会舍弃原有数据创造新的变量。
PCA的作用便是将数据维数压缩,尽可能降低原数据的维数,损失少量信息。
应用:回归分析或者聚类分析中。
API:
sklearn.decomposition.PCA(in_components=None)

实例:
1 | |
线性回归
Linear regression
线性回归是利用回归方程对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
通用公式: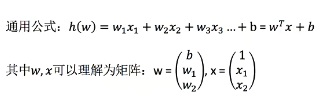
线性关系一定是线性模型
线性模型不一定是线性关系
缺点:不能解决拟合问题
线性回归API
普通最小二乘线性回归:
1 | |
通过使用SGD最小化正则化经验损失拟合线性模型。
SGD代表随机梯度下降(Stochastic gradient descent):每次对每个样本估计损失的梯度,并且沿着递减强度调度(aka学习速率)的路径更新模型。
1 | |

原理
损失和优化原理
对于线性回归模型,将模型与数据点之间的距离差之和做为衡量匹配好坏的标准,误差越小,匹配程度越大。
损失函数(最小二乘法):
现在我们要是模型的损失函数最小,则有两种方法:
梯度下降算法
梯度下降(Gradient Descent)是一个用来求函数最小值的算法,你可以用它来最小化任何代价函数,不只是线性回归中的代价函数。思想:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值,因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。
想象一下你正站立在山的这一点上,站立在你想象的公园这座红色山上,在梯度下降算法中,我们要做的就是旋转360度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。

梯度下降算法也有很多种:

正规方程
梯度下降法计算参数最优解,过程是对代价函数的每个参数求偏导,通过迭代算法一步步更新,直到收敛到全局最小值,从而得到最优参数。
正规方程是一次性求得最优解。
思想:对于一个简单函数,对参数求导,将其值置为0,就得到参数的值。
公式:正规方程与梯度下降法的比较
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量大时也能较好适用 | 需要计算公式,如果特征数量n较大则运算代价大 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
| 总结:取决于特征向量的个数,数量小于10000时,选择正规方程;大于10000,考虑梯度下降或其他算法。 |
回归性能评估
均方误差(Mean Squared Error)MSE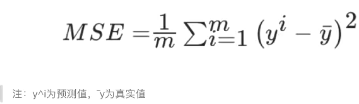
sklearn.metrics.mean_squared_error(y_true,y_pred)
过拟合欠拟合
过拟合:过拟合是指我们设计的模型过于紧密或精确的匹配了某特定数据,使得模型缺少泛化能力,而无法有效处理其他的、或未观测的数据的现象。
欠拟合:欠拟合的概念恰恰与过拟合相反;它是指相对于数据而言,我们的预测模型过于简单,无法有效反应数据的特征规律,因此也缺少了泛化能力。
解决方法:正则化
正则化(regularization)
正则化(Regularization)是一个可以防止机器学习算法过度拟合数据集的概念。
过拟合一般都是拟合模型的参数次项过大,正则化便是事先让这些高次项的系数接近于0,从而达到好的拟合效果。
通过在损失函数中引入惩罚项(Penalizing term)来实现这一点,该惩罚项为复杂曲线指定了更高的惩罚
- L2正则化:
损失函数+λ惩罚项 (λ称为正则化参数,如果选择的正则化参数过大,则会把所有的参数都最小化了造成欠拟合。)
它通过使高次项的参数接近于0来削弱某个特征的影响。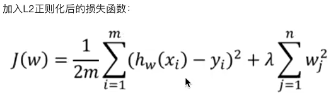
正则化力度越大,权重系数会越小
正则化力度越小,权重系数会越大 - L1正则化:
它通过使高次项的参数直接为0来削弱某个特征的影响。
岭回归
岭回归就是带L2正则化的线性回归,具有L2正则化的线性最小二乘法。
岭回归API:
sklearn.linear_model.Ridge
1 | |

逻辑回归
模型保存与加载
无监督学习 K-means
支持向量机
1. 支持向量机简介
支持向量机是由Vapnik经过多年的统计学习理论研究提出的一种能够较好的解决线性不可分问题的监督式学习算法。起初,支持向量机主要应用于模式识别和一些分类问题,在后来随着不敏感损失函数的引入衍生出了支持向量回归机,使得支持向量机在函数的回归和预测领域起到广泛的应用。
它能够执行线性或分线性分类、回归等任务,适用于中小型复杂数据集的分类。
supported vector machine,简单来讲就是寻找到一个超平面使样本分成两类,并使间隔最大。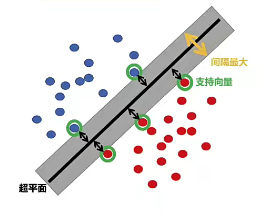
2. 超平面最大间隔介绍
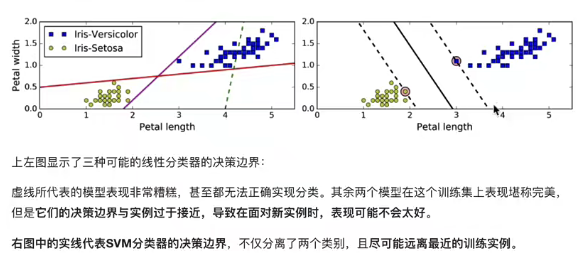
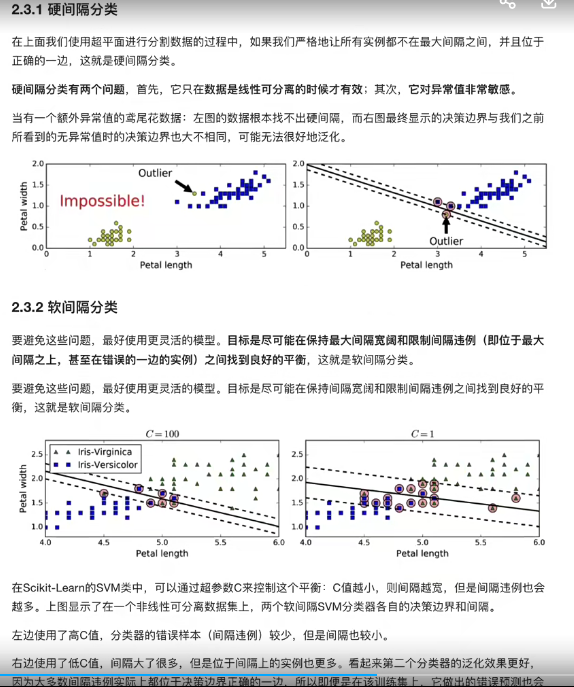
3. 硬间隔和软间隔
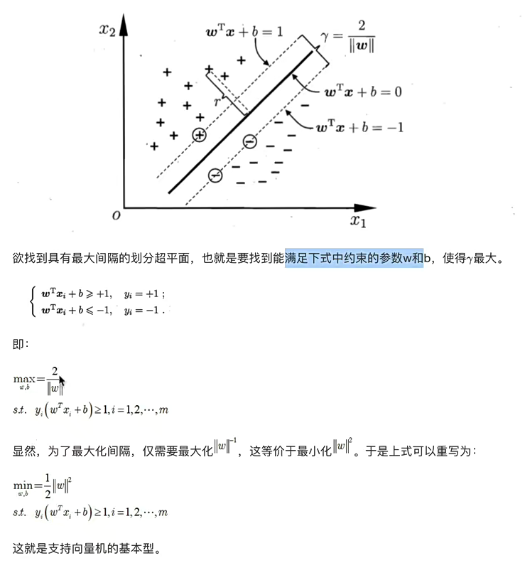
4. SVM算法原理
线性模型问题:
如果现在又这样一个数据集,其中有正样本,也有负样本,分别由源泉和X号来表示,可以看到这个数据集是线性可分的,存在一条直线把正负样本分开。我们把这条直线叫做一个决策边界,决策边界会有很多个,如下图所示两种,右图相比左图从直观上看是要比左图的分开效果是要差的,对于支持向量机,它将会选择左图,因为看起来是更稳健的决策界,这条决策边界有更大的距离,这个距离叫做间隔(margin,对应图中的d)。因此支持向量机有时被称为大间距分类器.
推导目标函数

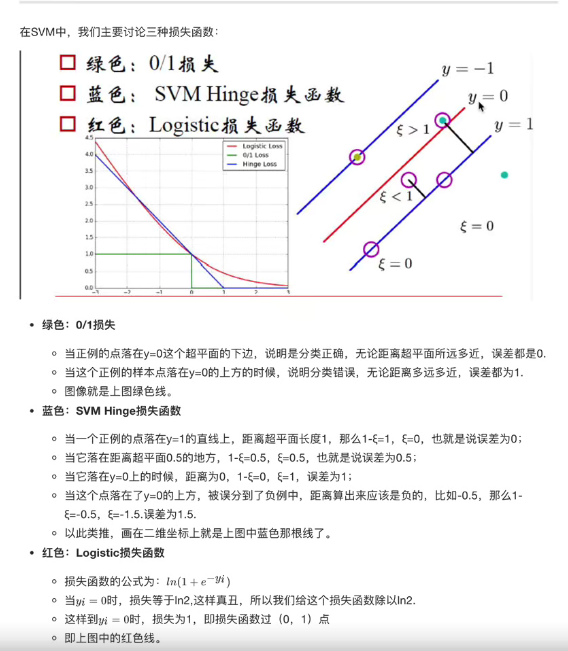
SVM损失函数
5. 核函数
核函数就是将原始的输入空间映射到新的特征空间。从而使得原本线性不可分的样本可能在核空间可分。
核函数的作用就是一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。

常见核函数:


6. SVM回归
让尽可能多的实例位于预测线上,同时限制间隔违例
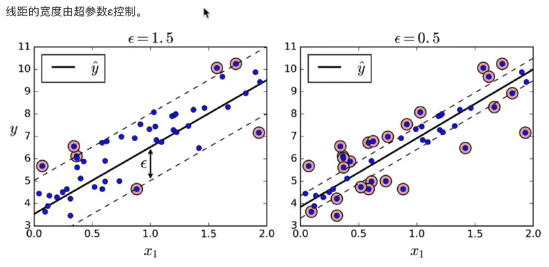
7. SVM API
SVM方法既可以用于分类,也可以用于回归和异常值检测。
SVM有很好的鲁棒性,对未知数据拥有很强的泛化能力,特别是在数据量较少的情况下,相较其他传统机器学习算法具有更优的性能
SVM模型流程:
- 对样本数据进行归一化
- 应用核函数对样本进行映射
- 用cross-validation和grid-search对超参数进行优选
- 用最优参数训练得到模型
- 测试

SVC


1 | |
8. SVM总结

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!