【PythohCrawler】
Python爬虫
爬虫简介
1.定义
网络爬虫就是模拟客户端发送网络请求,获取响应数据,一种按照一定的规则,自动的抓取万维网信息的程序或脚本
2.爬虫的应用:
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,因此爬虫应运而生,它不仅能够被使用在搜索引擎领域,而且在大数据分析,以及商业领域都得到了大规模的应用。
- 数据分析
在数据分析领域,网络爬虫通常是搜集海量数据的必备工具。对于数据分析师而言,要进行数据分析,首先要有数据源,而学习爬虫,就可以获取更多的数据源。在采集过程中,数据分析师可以按照自己目的去采集更有价值的数据,而过滤掉那些无效的数据。 - 商业领域
对于企业而言,及时地获取市场动态、产品信息至关重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等,当然如果贵公司有一个爬虫工程师的话,就可通过爬虫的方式取得想要的信息。
3.编写爬虫的流程:
- 先由 urllib 模块的 request 方法打开 URL 得到网页 HTML 对象。
- 使用浏览器打开网页源代码分析网页结构以及元素节点。
- 通过 Beautiful Soup 或则正则表达式提取数据。
- 存储数据到本地磁盘或数据库。
request库
Python 内置了 requests 模块,该模块主要用来发送 HTTP 请求并获取响应数据。Requests的主要功能及用途是用作发送网络请求,根据对方服务器的要求不同,可使用GET、POST和PUT等方式进行请求。并且可以对请求头进行伪装、使用代理访问等。
1 | |
requests 方法
requests 方法如下表:
| 方法 | 描述 |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
BeautifulSoup库
Beautiful Soup是一个从HTML或XML中提取数据的python库。
它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
Beautiful Soup库的基本使用
1 | |
对象介绍与创建:
对象:
代表要解析整个文档树,它支持遍历文档树和搜索文档树中描述的大部分的方法。
创建beautifulsoup对象:1
2from bs4 import beautifulsoup
soup=beautifulsoup=(html,'lxml') #后面的lxml是指定的解析器获取网页标签信息
1
2
3soup.title
soup.head
soup.a搜索文档树
对象的find方法:1
2
3
4
5
6
7find(self,name=Mone,attrs={},recursive=True,text=None,**kwargs)
参数:
name:标签名
attrs:属性字典
recursibe:是否递归循环查找
text:根据文本内容查找
可以指定上述参数的值来查找内容
正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式的大致匹配过程是:
- 依次拿出表达式和文本中的字符比较,
- 如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
- 如果表达式中有量词或边界,这个过程会稍微有一些不同。
正则表达式的语法规则
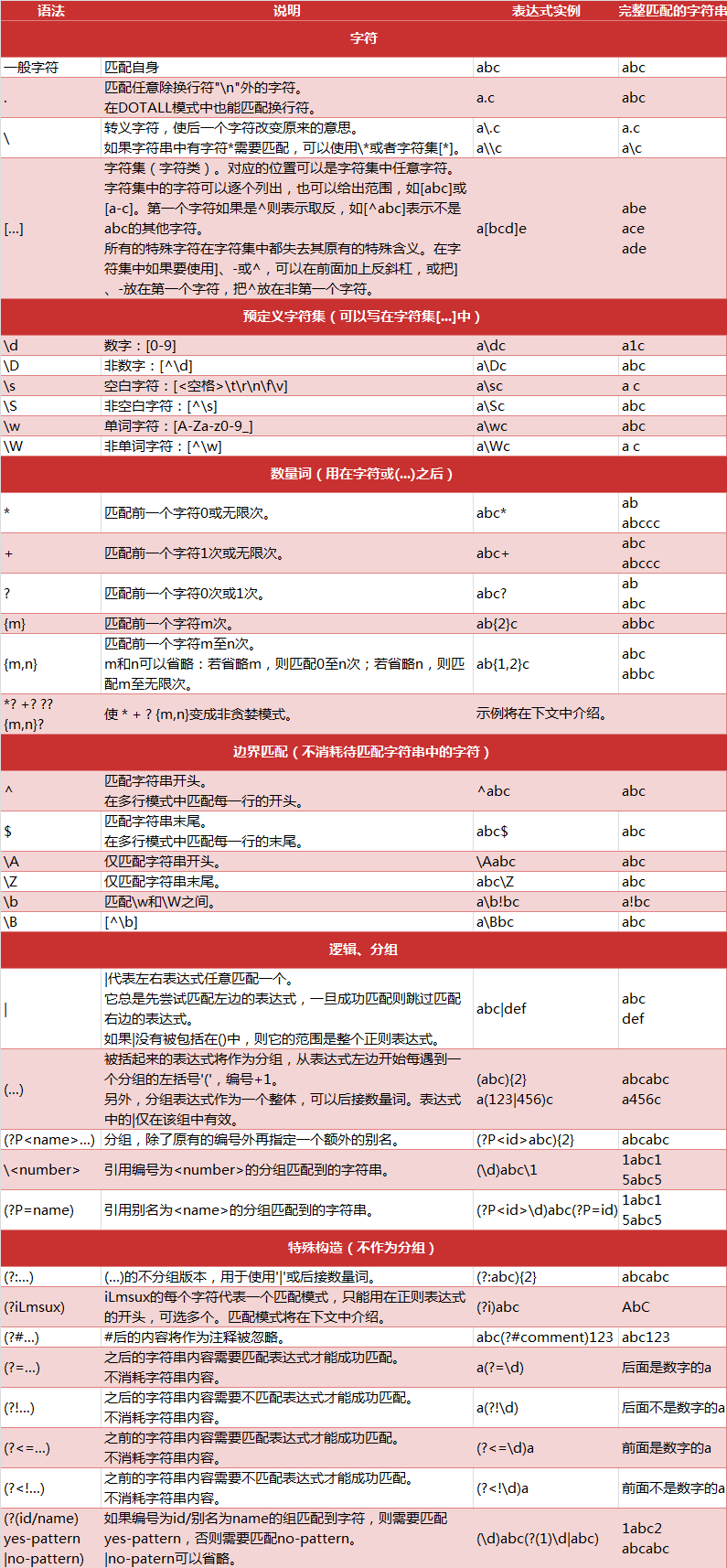
1 | |
1 | |
特点:
如果正则表达式中没有()则返回整个正则匹配的列表
如果正则表达式中有(),则返回()中匹配的内容列表,小括号两边东西都是负责确定提取数据的所在位置
反斜杠问题
与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
json模块
用于json和python数据之间的相互转换
| 函数 | 描述 |
|---|---|
| json.dumps | 将 Python 对象编码成 JSON 字符串 |
| json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
将 Python 对象编码成 JSON 字符串
1 | |
把json格式文件转换为Python类型数据
1 | |
爬取丁香园疫情数据
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!